
The Future of Software is defined by speed, quality, and the ability to overcome bottlenecks such as access to realistic test data and the complexity of testing environments. In this post, we explore how the synergy between synthetic data and digital twins is enabling companies to simulate real-world scenarios at an unprecedented scale, accelerating development cycles, minimizing risks, and ensuring application robustness in a future where efficiency and accuracy are the new norm.
Today, synthetic data and digital twins are powerful tools with applications across diverse industries, especially research and development, manufacturing, healthcare, and logistics.
Synthetic data is artificially generated to simulate real data, while digital twins are virtual replicas of physical systems or processes that enable simulation and optimization.
Both are important for organizations and companies because they enable behavior prediction, process optimization, improved decision-making, and accelerated innovation, while also mitigating risks and improving efficiency.
In the field of software engineering, they create a new environment: integration is necessary in the software development process and data management, and they technically impact program testing.
Conceptually, software testing is the process of evaluating software to identify errors and ensure it meets functional and non-functional requirements. Software quality refers to the degree to which software meets user needs and expectations, including reliability, usability, and performance. Essentially, testing is a tool for achieving and maintaining software quality.
In this sense, it is essential to ensure that the data used is representative and efficient in relation to the reality being modeled, while the modeling software is sufficiently robust and high-quality. The trend is that more and more software engineering processes will use synthetic data and digital twins, not only in design but also in implementation and testing.
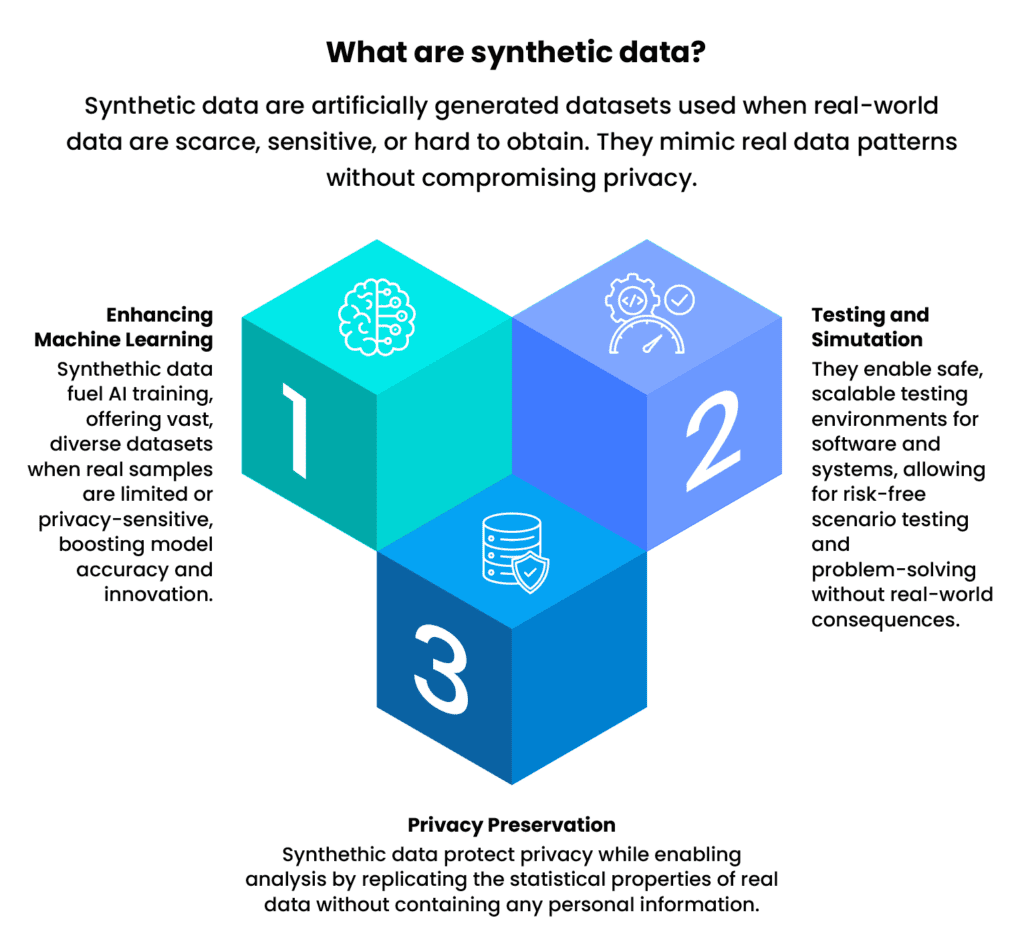
1. Exploring Synthetic Data in the Future of Software
Synthetic data is artificially generated through algorithms and models, designed to mimic the properties and statistical characteristics of real data without containing confidential or proprietary information.
What are they used for?
- When the amount of real data available is insufficient, or it is unbalanced or incomplete.
- When obtaining more data is impossible or expensive.
- When real data is protected by regulations.
A classic example of its use is in healthcare research, where obtaining numerous data from real patients is complex in various applied projects, and data synthesis methodologies exist.
This is a common area where data science and artificial intelligence must seek new solutions.
In fact, the generative adversarial network (GAN) methodology involves the simultaneous training of two neural network models: a generative model that captures the data distribution and a discriminative model that determines whether the sample is generated from the model or from the data distribution.
2. The Value of Digital Twins for the Future of Software
What do we mean by a digital twin? It’s a virtual replica of a physical object, system, or process that is created and updated in real time using data from sensors and other sources.
What is it used for? It serves to simulate, analyze, monitor, and optimize the behavior of the physical object in various situations, enabling more informed decisions and improving its performance, efficiency, and safety.
It allows testing conditions that don’t always occur in production, such as failures, extreme cases, and emergent behaviors. It generates continuous learning based on real data, adjusting simulations in real time.
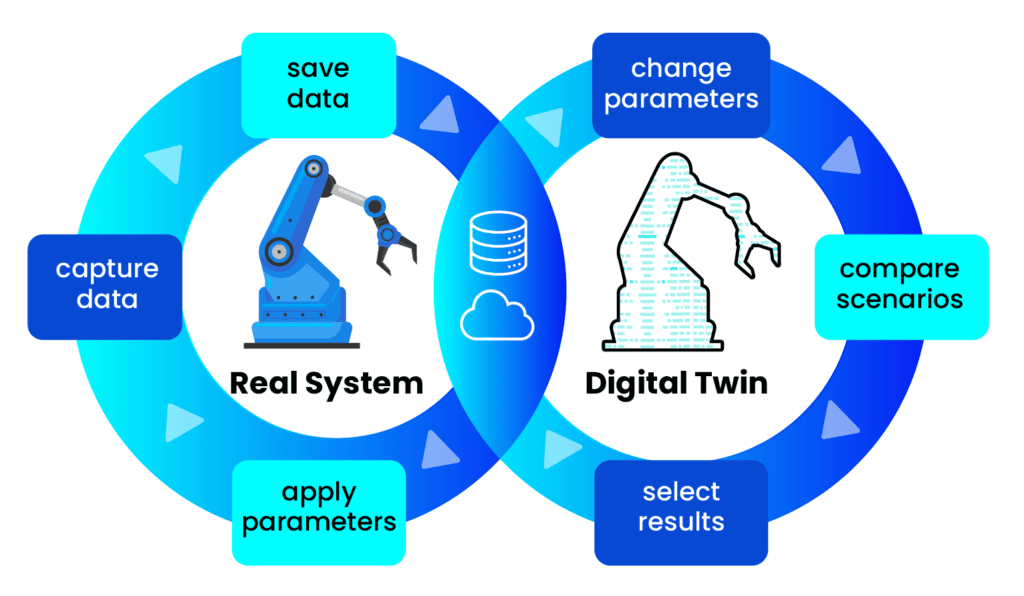
It reflects the complexity and conditions of the real world, allowing for:
A) Realistic simulation: Recreating production scenarios and conditions within a controlled virtual environment.
B) Predictive analytics: Simulating various scenarios and predicting outcomes without affecting the real system.
C) Cost-effective testing: Reducing the need for expensive physical testbeds and minimizing the risks associated with testing on real systems.
D) Accelerated testing: Execute numerous test cases and complex scenarios much faster than in a physical environment.
3. Integration of Synthetic Data and Digital Twins: Shaping the Future of Software
When integrated, synthetic data enhances the capabilities of digital twins in software testing.
In fact, it enables:
A) Simulation and testing environments
Synthetic data can be used to populate the virtual environment of a digital twin. Real-life conditions can be simulated without disrupting operations (this is augmented testing outside of operations, so it doesn’t cause process issues). The generation of synthetic user interaction data serves to accurately represent real-world usage patterns within the digital twin.
B) Increased predictive analytics
Extensive testing can be performed, reducing risks and costs. A clear example is the monitoring of traffic scenarios and people movements in a smart city, without disrupting operations or real traffic.
Or, in all energy consumption sensors, real data is constantly being collected. Synthesizing and simulating this data means imagining people, homes, appliances, vehicles, etc. that demand and consume energy according to certain usage patterns. This simulation would allow us to know, for example, if a city’s population grows by 10%, how much energy consumption would increase.
C) Efficiency and Resource Optimization
Tests are often very expensive, difficult, or very risky, for example in aviation. By using a digital twin of the aircraft, engineers can identify potential failures without using a physical prototype or destroying a real aircraft.
D) Testing of Complex Systems
Creating diverse, large-scale datasets to comprehensively test the performance and resilience of complex systems modeled by the digital twin. In logistics and manufacturing, processes can be optimized and distribution efficiency improved. In research and development, deeper data analysis of climate, energy, cities, ecosystems, and social organizations can be performed.
E) Facilitating AI and Machine Learning Testing
This involves providing a comprehensive dataset to train and test AI and machine learning models that are part of the software system within the digital twin.
This integrated approach undoubtedly enables organizations to perform more comprehensive, efficient, and secure software testing, ultimately resulting in higher-quality and more reliable applications.
4. Future Challenges and Questions in the Future of Software
Software testing and software engineering in general are evolving at the pace of new applications of data science and artificial intelligence. However, the use of software engineering to improve artificial intelligence and achieve the development of reliable and secure systems still has a long way to go.
It is clear that even the development of synthetic data and digital twins faces notable challenges and demanding processes to ensure software quality and reliability.
In this context, enormous coordination is required across technical, development, QA, and data science teams. Among the challenges to be addressed are:
- Ensuring that synthetic data is representative of real life and is not biased.
To achieve this, the testing and data quality process must be very thorough, as synthetic data can perpetuate biases in the algorithms themselves. The process is very demanding: if the data is not valid or realistic, the model’s results can be very poor.
- Creating digital twins requires a very deep understanding of the physical system to be modeled.
This requires complex simulations and very specific computational resources, including specialized software and modeling environments for system dynamics.
- Continuous updating of digital twins with real-time data to maintain accuracy and ensure the model fulfills its function.
This requires constant maintenance and monitoring. The healthcare industry is a very specific case, as population statistics and the evolution of new diseases, treatments, and drugs, as well as the development of medical technologies, are dynamic problems that require complex approaches.
- Aligning synthetic data with the digital twin model.
Ensuring that the generated data aligns with the parameters and behavior of the digital twin can be complex. Misalignments can lead to inaccurate test results. Therefore, very precise coordination is necessary.
Final Thoughts
Software testing has always been a fundamental pillar of software development, ensuring the functionality, security, and reliability of applications. As technology evolves rapidly, the software testing landscape is undergoing significant transformations.
The software testing market size was valued at $55.6 billion in 2024 and is estimated to reach $142.1 billion by 2037, growing at a compound annual growth rate (CAGR) of 7.5% over the forecast period (2025–2037). By 2025, the industry is projected to reach a value of $59.7 billion.
By 2025–2026, several key trends are expected to redefine software testing, making it faster, more efficient, and more accurate. From artificial intelligence to synthetic data and digital twins, these innovations are revolutionizing the industry.
The world of software testing is on the verge of a revolution: advances in AI, automation, and cloud technologies will transform testing, making it faster, more efficient, and more accurate. Shift-left approaches and continuous testing will allow teams to detect defects earlier, while AI model testing will ensure fairness and transparency.
As organizations embrace these trends, they must also prioritize security and privacy to comply with regulations and protect user data. By anticipating these developments, companies can deliver high-quality software that meets the demands of an increasingly digital world.
The future of software testing is bright, and those who adapt to these changes will be well positioned to thrive in the coming years.
If you’d like to learn more about future trends in AI, machine learning, and data science, stay tuned for updates on our blog.
