Balotaje: la ciencia de datos predice resultados electorales
Por Carlos Lizarralde, CEO y socio fundador de 7Puentes
El fracaso en la estimación de los resultados de los últimos comicios nacionales (ocurridos el pasado 25 de octubre) demostraron que las encuestas no estuvieron a la altura de las circunstancias. Métodos tradicionales como el boca de urna y la encuesta telefónica parecen haber perdido su valor predictivo. Incómodos por ese hecho, en 7Puentes, luego de unas horas brainstorming y hackathon en el lenguaje python y scikit, surgió un modelo para calcular los posibles resultados del balotaje presidencial, basado en los datos del escrutinio oficial publicados, un poco de intuición y, por supuesto, álgebra vectorial.
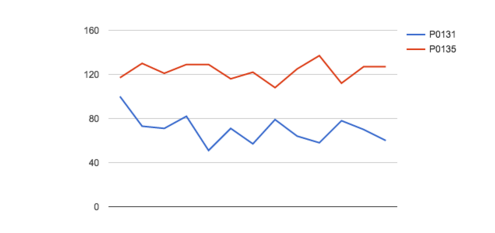
Tomemos en cuenta (para ilustrar el modelo) la correlación entre los vectores formados por los votos de un conjunto de mesas del Frente para la Victoria y de Cambiemos (en este ejemplo corresponden a la provincia de Buenos Aires, Departamento 009, Circuito 0098).

Observando este gráfico podemos ver que dicha correlación es bastante baja. Se puede ver a simple vista que cuando la cantidad de votos de una fuerza política sube, los de la otra disminuyen. Esto indica que ambas agrupaciones “compiten” por los votos, es decir, son antagónicas en la elección de los votantes. Esta observación nos llevó a plantear que si la no-correlación significaba competencia (lo que es un hecho fáctico y comprobable en el caso de la lista 131 del FPV y la 135 de Cambiemos) a mayor correlación lineal entre los vectores, mayor parecido entre el electorado de ambas fuerzas (la correlación la medimos calculando el coseno del ángulo entre los vectores).
El algoritmo para implementar el modelo es el siguiente:
Para cada circuito electoral y por cada una de las fuerzas que no compiten en balotaje (UNA, FIT, Progresistas y Compromiso Federal):
a) se calcula el vector de votos.
b) los votos se suman a aquella fuerza (de las que participan en el ballotage, claro) más cercana (con mayor correlación lineal).
c) se totalizan los votos que “ganó” cada una de las dos fuerzas que compitieron y se suman a los que ya habían conseguido (asumimos también que las fuerzas que compiten conservarán sus votos en el balotaje).
También hicimos el ejercicio de vectorizar las fuerzas no sólo por circuito, sino también por departamento y por provincia esperando que el modelo sea estable prevaleciendo ante las diferencias regionales.
Resultados
Los resultados presentados abajo, en forma de tabla, indican que Daniel Scioli sería el próximo presidente de los argentinos.

El hecho de que, sin importar el nivel de detalle y a pesar de la diferencia de resolución con la que analizamos los datos, el resultado se mantenga estable en los distintos niveles (siempre ganó la misma fuerza), sirve como forma de validación del modelo.


Por otro lado, si calculamos los resultados parciales en cada nivel podemos ver que la media de la distribución del resultado está en la estimación que calculamos (tanto a nivel provincial como a nivel departamental).
Conclusión
Estos resultados no salieron de una encuesta sino del análisis de los datos provisorios de la última elección. Nada es absoluto ni definitivo, todas son estimaciones y las cifras arrojadas por las encuestas también lo son.
Tal vez nuestras conclusiones disten de lo que están reflejando por estos días algunas encuestas de las distintas consultoras a nivel nacional. No estamos haciendo una valoración subjetiva sino que simplemente proponemos un método, una mirada alternativa y desinteresada.
Fuente de Datos: http://elecciones.gob.ar/articulo_princ.php?secc=2&sub_secc=55
Lenguaje: Python https://gist.github.com/clizarralde/59deac983823392508d4